


Цель поста – продемонстрировать создание тестовой конфигурации кластера высокой доступности с использованием Red Hat Cluster Suite и кластерной файловой системы Global File System.
При создании HA-кластера используем следующее ПО/технологии. Все они являются полностью открытыми и для них доступен исходный код:
- Red Hat Enterprise Linux Advanced Platform 5.1
– Red Hat Cluster Suite (в том числе web-интерфейс Conga, qdiskd и clvmd);
– Global File System;
– udev.
Вместо RHEL можно использовать CentOS, Scientific Linux и другие подобные.
Для создания демо-стенда использовались два физических сервера с внешним дисковым массивом, подключенным через FC, и одна управляющая станция, на которой была установлена web-консоль luci (проект Conga). Данная конфигурация избыточна, и все эти шаги можно повторить с использованием одного физического сервера, предоставляющего доступ к разделу по iSCSI двум виртуальным машинам, которые работают на том же сервере. В этом случае luci также можно было бы запускать на хост-системе или, в зависимости от числа доступных ресурсов, на сервере “поднять” третью виртуальную машину. Использование физических серверов критично в случае, если вы в качестве серверного ресурса планируете запускать виртуальные машины – HA + “живая миграция” (т.е. примерно то, что обеспечивает VMWareHA, и чего ждем в Windows Server 2008 R2).
Важно. Хотя, по информации, приведенной в этом посте, можно повторить все шаги и по аналогии настроить свой кластер, но информации будет явно не достаточно для понимания всех деталей работы, команд и планирования развертывания кластера. Для дальнейшего изучения материала рекомендую обратиться к официальной документации Red Hat, свободно доступной на сайте Red Hat как в виде PDF, так и HTML. Пост в блоге не заменяет чтения сотен страниц документации. Также нужно заметить, что решение задействовать GFS и использование кластера именно из двух узлов не является необходимым/оптимальным решением для рассмотренной задачи (отказоустойчивый web-сервер). Решение продиктовано желанием продемонстрировать использование большего числа технологий (GFS и кворумный диск). Более того, использование web-сервера как кластерной службы выбрано исключительно для демонстрации и из-за простоты базовой настройки. Для достижения результата в каждом конкретном шаге также, как правило, возможно воспользоваться разными инструментами: system-config-cluster, Conga или командная строка.
Создаем кластер, используя web-интерфейс (проект Conga)
Наиболее простой способ создать кластер – использовать Conga. Также стоит использовать данный интерфейс, когда мы хотим управлять из одной точки несколькими кластерами. Для того чтобы избежать некоторых “шероховатостей” в дальнейшем, убедимся, что на всех кластерах в /etc/hosts имя узла не присутствует в одной строчке с localhost, как это прописывает по умолчанию Anaconda. Кроме того, для независимости кластера от работы службы DNS лучше всего также прописать в hosts все остальные узлы и машину, где будет установлена luci. Кроме того, предполагается, что всем машинам доступны группы Cluster и Cluster Storage через RHN, Satellite или локальный репозиторий.
На управляющей станции устанавливаем web-консоль:
[root@server1 ~]# yum -y install luci
[root@server1 ~]# luci_admin init
Задаем пароль администратора luci.
[root@server1 ~]# service luci restart
Shutting down luci: [ OK ]
Starting luci: [ OK ]
Point your web browser to https://server1.example.com:8084 to access luci
А на обоих узлах кластера агента, который работает в паре c luci:
[root@node1 ~]# yum -y install ricci
[root@node1 ~]# service ricci restart; chkconfig ricci on
Теперь можно как нам и предложили зайти в web-интерфейс server1.example.com:8084. Со вкладки Clucter выбираем создание нового кластера:
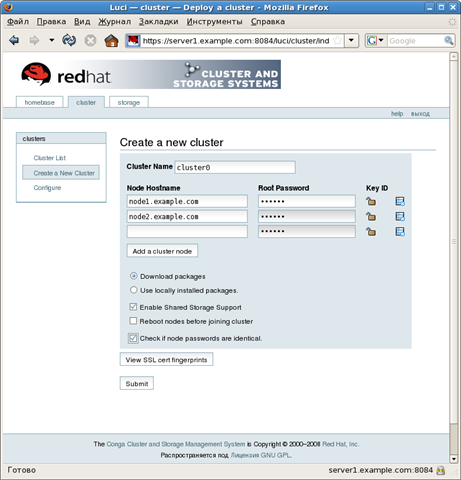
После нажатия кнопки Submit узлы кластера скачивают и устанавливают соответствующие пакеты. По окончании процесса мы должны увидеть такую картину:

Настраиваем постоянные имена для разделов на дисковом массиве
Данный шаг необходим в ряде случаев, например, когда мы не можем гарантировать, что после перезагрузки каждый раздел будет иметь то же имя, что и перед прошлым циклом перезагрузки (iSCSI), или, например, в случае различного числа дисков на узлах кластера, когда один и тот же LUN будет выглядеть на узлах по-разному:
[root@node1 ~]# fdisk -l
...
Disk /dev/sdc: 72.8 GB, 72837857280 bytes
255 heads, 63 sectors/track, 8855 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System
/dev/sdc1 1 13 104391 83 Linux
…
[root@node2 ~]# fdisk -l
…
Disk /dev/sdd: 72.8 GB, 72837857280 bytes
255 heads, 63 sectors/track, 8855 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System
/dev/sdd1 1 13 104391 83 Linux
…
В первом случае наш рабочий LUN на массиве – это sdc, а во втором – sdd. Данную проблему можно решить при помощи правила udev. В качестве альтернативы при использовании LVM и ext3 можно было бы воспользоваться UUID или метками ФС. Однако, правило udev более универсально.
Получим идентификатор нашего рабочего диска:
[root@node2 ~]# scsi_id -g -s /block/sdd
3600805f3001d3200a1e3ff9f259f0003
На каждом из узлов напишем правило udev (за подробностями – к документации):
[root@node1 ~]# cat /etc/udev/rules.d/75-custom.rules
KERNEL=="sd*", BUS=="scsi", PROGRAM=="/sbin/scsi_id -g -s %p",RESULT=="3600805f3001d3200a1e3ff9f259f0003", SYMLINK+="mydata%n"
В итоге на обоих узлах получаем картину:
[root@node1 ~]# ls -l /dev/my*
lrwxrwxrwx 1 root root 3 Dec 2 12:54 /dev/mydata -> sdc
lrwxrwxrwx 1 root root 4 Dec 2 12:54 /dev/mydata1 -> sdc1
[root@node2 ~]# ls -l /dev/my*
lrwxrwxrwx 1 root root 3 Aug 1 13:58 /dev/mydata -> sdd
lrwxrwxrwx 1 root root 4 Aug 1 13:58 /dev/mydata1 -> sdd1
Еще один вариант – это воспользоваться стандартно создаваемыми симлинками в /dev/disk/by-id/.
Fencing
В Red Hat Cluster Suite поддерживается большое число агентов, в том числе для ряда ИБП APC, что радует – HP iLO и IBM Blade Center, виртуальных машин Xen, коммутаторов McData, Brocade. Однако, например, Cisco MDS, насколько я знаю, “родными” средствами “гасить” нельзя. В luci настройка fencing производится на вкладке Cluster в свойствах кластера и пункте меню Shared Fence Devices. Снимки с экрана пропустим :)
Добавляем кворумный диск
Получившийся кластер состоит из двух узлов. Чтобы разрешить проблему разделения кластера на две независимые части, когда каждый из узлов думает что он единственный уцелевший и продолжает изменять данные на диске, добавим кворумный диск. Просмотрим состояние нашего кластера. Два узла, флаг специального двух-узлового режима и ни одного сервиса:
[root@node1 ~]# clustat
Member Status: Quorate
Member Name ID Status
—— —- —- ——
node2.example.com 1 Online
node1.example.com 2 Online, Local
[root@node1 ~]# cman_tool status
Version: 6.0.1
Config Version: 1
Cluster Name: cluster0
Cluster Id: 26776
Cluster Member: Yes
Cluster Generation: 140
Membership state: Cluster-Member
Nodes: 2
Expected votes: 1
Total votes: 2
Quorum: 1
Active subsystems: 8
Flags: 2node
Ports Bound: 0 11 177
Node name: node1.example.com
Node ID: 2
Multicast addresses: 239.192.104.1
Node addresses: 192.168.50.140
В качестве кластерного диска используем первый раздел на общем диске:
[root@node1 ~]# mkqdisk -c /dev/mydata1 -l myqdisk
mkqdisk v0.5.1
Writing new quorum disk label 'myqdisk' to /dev/mydata1.
WARNING: About to destroy all data on /dev/mydata1; proceed [N/y] ? y
Initializing status block for node 1...
...
[root@node1 ~]# mkqdisk -L
mkqdisk v0.5.1
/dev/sdc1:
Magic: eb7a62c2
Label: myqdisk
Created: Tue Dec 2 13:12:29 2008
Host: node1.example.com
Теперь необходимо вручную на одном из узлов убрать флаг, говорящий о том, что кластер в особой двухнодовой конфигурации (luci ставит этот флаг автоматом), и увеличить число голосов на один. Кроме того, необходимо увеличить версию конфигурационного файла:
[root@node1 ~]# vi /etc/cluster/cluster.conf
cluster alias="cluster0" config_version="3" name="cluster0"
...
cman expected_votes="3" two_node="0"/
Даем команду узлам кластера обновить конфигурацию:
[root@node1 ~]# ccs_tool update /etc/cluster/cluster.conf
Config file updated from version 2 to 3
Update complete.
Стартуем сервис qdiskd, который уже привнесен нам на узлы пакетом cman:
[root@node2 ~]# chkconfig qdiskd on; service qdiskd start
Starting the Quorum Disk Daemon: [ OK ]
Теперь в luci добавляем кворумный раздел. В качестве проверки будем пинговать шлюз по умолчанию:

За объяснением параметров идем к документации. В итоге в clustat мы получаем следующую картину:
[root@node1 ~]# clustat
Member Status: Quorate
Member Name ID Status
—— —- —- ——
node2.example.com 1 Online
node1.example.com 2 Online, Local
/dev/mydata1 0 Online, Quorum Disk
Раздел GFS
Если в двух словах, то про сетевые файловые системы, в том числе и GFS, Андрей Меганов писал в блоге. А дальше, традиционно, читаем документацию.
К настоящему моменту Conga уже должна была установить все необходимые пакеты. Для гарантии того, что тип блокировок LVM2 сменен с stand-alone на cluster-wide, отдадим команду:
[root@node2 ~]# lvmconf --enable-cluster
После чего (пере)запустим clvmd. Далее создадим на общем диске раздел под GFS:
[root@node1 ~]# fdisk /dev/mydata
На обоих узлах перечитаем таблицу разделов:
[root@node1 ~]# partprobe
[root@node1 ~]# fdisk -l
Disk /dev/sdc: 72.8 GB, 72837857280 bytes
255 heads, 63 sectors/track, 8855 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Device Boot Start End Blocks Id System
/dev/sdc1 * 1 13 104391 83 Linux
/dev/sdc2 14 6093 48837600 8e Linux LVM
На новом разделе создадим логический том, который, благодаря clvmd, будет доступен на всех узлах кластера:
[root@node1 ~]# pvcreate /dev/mydata2
Physical volume "/dev/mydata2" successfully created
[root@node1 ~]# vgcreate vgcluster /dev/mydata2
Volume group "vgcluster" successfully created
[root@node1 ~]# vgdisplay | grep Free
Free PE / Size 11923 / 46.57 GB
Free PE / Size 0 / 0
[root@node1 ~]# lvcreate -l 11923 -n gfsvol vgcluster
В случае, если последняя команда отработает с ошибкой, workaround:
[root@node2 ~]# service clvmd stop
Stopping clvm: [ OK ]
[root@node2 ~]# rm /etc/lvm/cache/.cache
rm: remove regular file `/etc/lvm/cache/.cache'? y
[root@node2 ~]# pvscan
connect() failed on local socket: Connection refused
WARNING: Falling back to local file-based locking.
Volume Groups with the clustered attribute will be inaccessible.
PV /dev/mydata2 VG vgcluster lvm2 [46.57 GB / 0 free]
PV /dev/sdb1 VG VolGroup00 lvm2 [149.03 GB / 0 free]
PV /dev/sda2 VG VolGroup00 lvm2 [74.41 GB / 0 free]
Total: 3 [270.01 GB] / in use: 3 [270.01 GB] / in no VG: 0 [0 ]
[root@node2 ~]# vgscan
connect() failed on local socket: Connection refused
WARNING: Falling back to local file-based locking.
Volume Groups with the clustered attribute will be inaccessible.
Reading all physical volumes. This may take a while...
Skipping clustered volume group vgcluster
Found volume group "VolGroup00" using metadata type lvm2
[root@node2 ~]# lvscan
connect() failed on local socket: Connection refused
WARNING: Falling back to local file-based locking.
Volume Groups with the clustered attribute will be inaccessible.
Skipping clustered volume group vgcluster
ACTIVE '/dev/VolGroup00/LogVol00' [221.50 GB] inherit
ACTIVE '/dev/VolGroup00/LogVol01' [1.94 GB] inherit
[root@node1 ~]# service clvmd start
Starting clvmd: [ OK ]
Activating VGs: 1 logical volume(s) in volume group “vgcluster” now active
2 logical volume(s) in volume group “VolGroup00″ now active
[ OK ]
Создаем файловую систему (один лишний журнал “про запас”):
[root@node1 ~]# gfs_mkfs -p lock_dlm -t cluster0:share -j 3 /dev/vgcluster/gfsvol
Пробуем смонтировать:
[root@node1 ~]# mount /dev/vgcluster/gfsvol /var/www/html
[root@node1 ~]# mount
/dev/mapper/VolGroup00-LogVol00 on / type ext3 (rw)
proc on /proc type proc (rw)
sysfs on /sys type sysfs (rw)
devpts on /dev/pts type devpts (rw,gid=5,mode=620)
/dev/sda1 on /boot type ext3 (rw)
tmpfs on /dev/shm type tmpfs (rw)
none on /proc/sys/fs/binfmt_misc type binfmt_misc (rw)
sunrpc on /var/lib/nfs/rpc_pipefs type rpc_pipefs (rw)
none on /sys/kernel/config type configfs (rw)
/dev/mapper/vgcluster-gfsvol on /var/www/html type gfs (rw,hostdata=jid=0:id=131074:first=1)
Информация о файловой системе:
[root@node1 ~]# gfs_tool df /var/www/html
/var/lib/xen/images:
SB lock proto = "lock_dlm"
SB lock table = "cluster0:share"
SB ondisk format = 1309
SB multihost format = 1401
Block size = 4096
Journals = 3
Resource Groups = 186
Mounted lock proto = "lock_dlm"
Mounted lock table = "cluster0:share"
Mounted host data = "jid=0:id=131074:first=1"
Journal number = 0
Lock module flags = 0
Local flocks = FALSE
Local caching = FALSE
Oopses OK = FALSE
Type Total Used Free use%
------------------------------------------------------------------------
inodes 5 5 0 100%
metadata 5 5 0 100%
data 12109426 0 12109426 0%
Добавляем строчку в /etc/fstab:
/dev/vgcluster/gfsvol /var/www/html gfs defaults 0 0
Создание кластерного ресурса
Остался последний шаг – создаем службу, которая будет хранить, и, если необходимо, изменять данные на GFS. С httpd пример не очень хороший, зато делается просто. На всех узлах:
[root@node2 ~]# yum -y install httpd
На одном из узлов:
[root@node2 ~]# vi /var/www/html/index.html
Теперь в web-интерфейсе:

Проверяем:
[root@server1 ~]# elinks -dump http://192.168.50.146
My web Service!
И с любого из узлов:
[root@node1 ~]# clustat
Member Status: Quorate
Member Name ID Status
—— —- —- ——
node2.example.com 1 Online
node1.example.com 2 Online, Local
/dev/mydata1 0 Online, Quorum Disk
Service Name Owner (Last) State
——- —- —– —— —–
service:webservice node2.example.com started
Теперь можно через web-интерфейс или из командной строки поперекидывать сервис с узла на узел, сымитировать падение узла, добавить скрипт, который будет каким-то образом менять данные, или добавить более интересный сервис в созданный HA-кластер.
Автор: Андрей Маркелов
Постовой
Всё самое интересное о Германии на de-web.ru.
Мониторинг курсов обмена, обменных пунктов.