


В какой-то момент использование единственного сервера LDAP может перестать удовлетворять вашим потребностям. Возможность выхода из строя сервера LDAP в вашей организации может оказаться неприемлемой, или же нагрузка на сервер может оказаться достаточно высокой, и вы решите распределить ее между несколькими серверам. Неважно, по какой причине, но у вас может возникнуть потребность в использовании нескольких серверов.
Вы можете разместить отдельные части каталога LDAP на нескольких различных серверах, однако это ведет к снижению уровня надежности, не говоря о сложности правильного распределения запросов. В идеальном случае на каждом сервере содержится одинаковая копия каталога. Все изменения, произошедшие на любом из серверов, передаются на остальные серверы определенным способом, обеспечивающим актуальность данных в любой момент времени. Этот процесс называется replication.
Этот сценарий, называющийся multi-masterрепликацией, является довольно сложным, поскольку в этом случае не существует единственного, четко определенного сервера, управляющего данными. Чаще всего используется репликация master-slave, при которой один главный (master) сервер управляет всеми изменениями каталога и рассылает их на подчиненные (slave) серверы. Запросы LDAP при этом могут быть обработаны любым из серверов. Данная схема может быть расширена до репликации с использованием узла реплики, когда данные с главного сервера реплицируются на один подчиненный сервер, а он в свою очередь реплицирует эти данные на все остальные подчиненные серверы.
В OpenLDAP существует два метода репликации. В первом методе используется slurpd – отдельный демон, который отслеживает изменения на главном сервере и передает их на подчиненные серверы. Во втором методе используется встроенный механизм репликации LDAP Sync сервера OpenLDAP, также известный как syncrepl. Репликация посредством slurpd считается устаревшей, и пользователям все больше предлагается использовать syncrepl. В этом разделе будут рассмотрены оба этих метода.
Репликация посредством slurpd
Репликация посредством slurpd является извещающей (push) репликацией, при которой главный сервер извещает об изменениях все подчиненные серверы. Если клиент пытается обновить данные на подчиненном сервере, этот сервер посылает клиенту так называемую возвращаемую ссылку (referral), перенаправляющую его на главный сервер. За подачу повторного запроса на главный сервер отвечает клиентский компьютер. Slurpd является отдельным демоном и настраивается в файле slapd.conf.
Обработка данных в модели репликации slurpd
Главный сервер – это сервер, обрабатывающий все поступающие от клиентов запросы на изменение каталога и содержащий достоверный источник данных. Любые изменения, произошедшие в дереве каталога главного сервера, записываются в журнал репликации, за которым наблюдает демон slurpd. Обнаружив изменения в журнале репликации, slurpd извещает о них все подчиненные серверы.
На рисунке 1 изображена схема работы демона slurpd.
Рисунок 1. Обработка данных в модели репликации slurpd
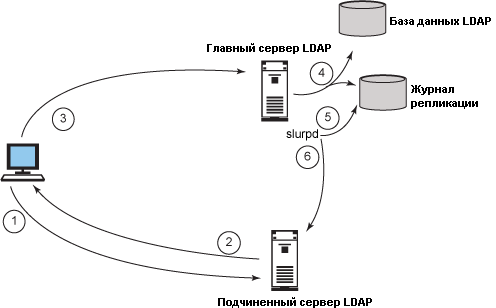
Описание процесса:
- Клиентский компьютер посылает запрос на обновление данных, который случайным образом попадает на подчиненный сервер.
- Подчиненный сервер знает о том, что он может выполнять операции записи только в случае получения их от своего партнера по репликации, и поэтому посылает клиенту возвращаемую ссылку, перенаправляющую его на главный сервер.
- Клиент повторно посылает запрос на обновление данных, обращаясь к главному серверу.
- Главный сервер выполняет обновление данных и записывает изменения в журнал репликации.
- Slurpd, который также запущен на главном сервере, обнаруживает изменения в журнале репликации.
- Slurpd направляет изменения на подчиненный сервер.
Таким образом, подчиненные серверы могут быть синхронизированы с главным сервером с небольшой задержкой. Slurpd всегда знает, какие подчиненные сервера нуждаются в обновлении, если произошла какая-либо задержка или сбой.
Настройка slurpd
Настройка репликации посредством slurpd состоит из следующих шагов:
- Создание учетной записи, которую slurpd будет использовать для аутентификации подчиненной реплики.
- Настройка имени подчиненного сервера на главном сервере.
- Настройка подчиненного сервера в качестве реплики, в том числе настройка необходимых списков управления доступом.
- Копирование базы данных с главного сервера на подчиненный сервер.
Создание учетной записи реплики не представляет особой сложности. Единственным требованием для этого является наличие в учетной записи атрибута userPassword. Вы можете использовать класс объекта inetOrgPerson objectClass, как в случае создания учетных записей, принадлежащих служащим, или более общий класс объекта, такой как account, добавив к нему вспомогательный класс simpleSecurityObject. Возвращаясь к первому руководству, вспомним, что структурные классы объектов описывают запись (и поэтому вы можете использовать только один класс объекта для каждой записи), тогда как вспомогательные классы объектов добавляют атрибуты к записи независимо от ее структурного класса. В листинге 7 приведен код в LDIF-формате (LDAP Data Interchange Format – формат обмена данными LDAP) для добавления учетной записи реплики.
Листинг 7. LDIF код для добавления учетной записи реплики
dn: uid=replica1,dc=ertw,dc=com uid: replica1 userPassword: replica1 description: Account for replication to slave1 objectClass: simpleSecurityObject objectClass: account |
В листинге 7 представлена простая запись, содержащая только имя пользователя, пароль и описание, чего вполне достаточно для целей репликации. Описание не является обязательным, однако рекомендуется использовать его в целях документирования. Запомните пароль – он понадобится на следующем шаге!
Теперь для работы slurpd необходимо настроить главный сервер на сохранение всех изменений в журнале репликации, а также настроить реплику. Важно помнить о том, что slurpd извещает об изменениях все подчиненные серверы, а его параметры конфигурации настраиваются в файле slapd.conf. Это в свою очередь поможет вам помнить о том, где нужно настраивать репликацию, и о том, что учетные данные для аутентификации располагаются на главном сервере. Поскольку учетные данные являются частью дерева каталога, подчиненный сервер всегда сможет проверить их. В листинге 8 приведены настройки главного сервера, обеспечивающие возможность репликации.
Листинг 8. Настройка репликации посредством slurpd на главном сервере
replica uri=ldap://slaveserver.ertw.com suffix="dc=ertw,dc=com" binddn="uid=replica1,dc=ertw,dc=com" credentials="replica1" bindmethod=simplereplogfile /var/tmp/replicationlog |
Настройка репликации происходит в режиме базы данных, поэтому убедитесь, что команда replicareplica стоит где-нибудь после настройки первого параметра database. Команда replicaсодержит ряд параметров в формате параметр=значение. Параметр uriопределяет имя или IP-адрес подчиненного сервера в формате унифицированного идентификатора ресурса (Uniform Resource Identifier, URI). Перед именем подчиненного сервера ставится префикс ldap://.
После того, как вы указали имя подчиненного сервера, вы можете указать с помощью параметра suffix необязательное имя базы данных для репликации. По умолчанию реплицируются все базы данных. Заключительным требованием является предоставление информации об учетных данных, чтобы slurpd мог подключаться к указанной ссылке uri. Для выполнения простой аутентификации вам будет достаточно настроить параметры binddn, bindmethod и credentials (параметр userPassword был настроен вами ранее).
На заключительном этапе настройки главного сервера необходимо указать службе slapd, где должен храниться журнал репликации. Необходимо указать полный путь, поскольку относительные пути не будут работать. Вам не нужно беспокоиться о создании файла журнала, поскольку slapd сделает это за вас; тем не менее, указанный вами путь должен быть доступен для записи пользователю, от имени которого выполняются демоны slapd и slurpd.
На подчиненном сервере вы должны настроить учетную запись репликации, а также указать, что получая запросы на изменение данных, он должен перенаправлять клиентов на главный сервер с помощью возвращаемой ссылки.
Листинг 9. Конфигурация подчиненного сервера
updatedn uid=replica1,dc=ertw,dc=com updateref ldap://masterserver.ertw.com |
Значением параметра updatednявляется учетная запись, созданная ранее на главном сервере. Эту учетную запись будет использовать демон slurpd для извещения подчиненных серверов об изменениях, произошедших в дереве каталога. Параметр updateref – это еще одна ссылка URI, указывающая на главный сервер LDAP. В листинге 10 приведен пример обновления клиентом подчиненного сервера и получения возвращаемой ссылки после настройки вышеуказанной конфигурации.
Листинг 10. Получение клиентом возвращаемой ссылки при попытке обновления данных на подчиненном сервере
[root@slave openldap]# ldapadd -x -D cn=root,dc=ertw,dc=com -w mypass -f newaccount.ldif adding new entry "cn=David Walberg,ou=people,dc=ertw,dc=com" ldap_add: Referral (10) referrals: ldap://masterserver.ertw.com/cn=David%20Walberg,ou=People,dc=ertw,dc=com |
Клиент командной строки OpenLDAP не переходит по возвращаемым ссылкам, но другие библиотеки LDAP делают это. Если вы используете LDAP в окружении с работающей репликацией, вы должны убедиться, что ваши приложения корректно переходят по возвращаемым ссылкам.
На заключительном этапе настройки процесса репликации необходимо обеспечить идентичность базы данных на главном и подчиненном серверах. Для этого выполните следующие шаги:
- Остановите главный сервер LDAP.
- Остановите подчиненный сервер LDAP.
- Скопируйте все файлы базы данных с главного сервера на подчиненный сервер.
- Запустите главный и подчиненный серверы.
- Запустите демон slurpd.
Перед копированием базы данных оба сервера LDAP должны быть остановлены для того, чтобы во время этой процедуры в каталоге не могли произойти какие-либо изменения. Крайне важно, чтобы оба сервера начали работу с идентичным набором данных, иначе впоследствии может произойти их рассинхронизация. Репликация посредством slurpd, по существу, выполняет на подчиненном сервере все те же транзакции, что происходят на главном сервере, поэтому любые расхождения могут привести к проблемам.
В зависимости от дистрибутива и сценариев загрузки операционной системы slurpd может автоматически запускаться вместе с slapd. Если демон slurpd не запускается автоматически, запустите его вручную из командной строки, выполнив команду slurpd.
Прежде чем двигаться дальше, у вас должна быть настроена работающая репликация. Создайте учетную запись на главном сервере и проверьте работу службы репликации. Убедитесь также, что при получении запросов на обновление данных подчиненный сервер посылает клиенту возвращаемые ссылки.
Мониторинг репликации
Очень важно уметь выполнять мониторинг репликации, поскольку в процессе работы могут возникать различные ошибки, приводящие к рассинхронизации данных. Эти же знания пригодятся и при отладке.
Файлы slurpd хранятся в каталоге var/lib/ldap/replica (отдельно от журнала репликации службы slapd). В этом каталоге содержатся собственные журналы репликации службы slurpd и прочие так называемые reject-файлы (файлы отклонения). Если попытка slurpd обновить подчиненный сервер оканчивается неудачей, то данные сохраняются в файл с расширением .rej. В этом файле содержится LDIF код записи, а также описание возвращенной сервером ошибки, например, ERROR: Already exists. В листинге 11 приведен пример reject-файла, содержащего другую ошибку.
Листинг 11. Reject-файл репликации
ERROR: Invalid DN syntax: invalid DN replica: slaveserver.ertw.com:389 time: 1203798375.0 dn: sendmailMTAKey=testing,ou=aliases,dc=ertw,dc=com changetype: add objectClass: sendmailMTAAliasObject sendmailMTAAliasGrouping: aliases sendmailMTACluster: external sendmailMTAKey: testing sendmailMTAAliasValue: testinglist@ertw.com structuralObjectClass: sendmailMTAAliasObject entryUUID: 5375b66c-7699-102c-822b-fbf5b7bc4860 creatorsName: cn=root,dc=ertw,dc=com createTimestamp: 20080223202615Z entryCSN: 20080223202615Z#000000#00#000000 modifiersName: cn=root,dc=ertw,dc=com modifyTimestamp: 20080223202615Z |
Файл отклонения, приведенный в листинге 11, начинается с текстового описания ошибки (“ERROR: Invalid DN syntax: invalid DN”), после которого следует код в формате LDIF. Обратите внимание на то, что первым атрибутом является replica – имя реплики, которая не смогла выполнить обновление, а вторым атрибутом является time – время возникновения ошибки (в формате времени UNIX). Следующие несколько атрибутов относятся к записи, которая была отклонена.
Последние семь атрибутов называются операционными атрибутами. Эти атрибуты не относятся к исходному обновлению, а были добавлены сервером LDAP в целях внутреннего мониторинга. Записи LDAP был присвоен универсальный уникальный идентификатор (Universally Unique Identifier, UUID), а также некоторая информация о том, когда и кем эта запись изменялась.
Ошибка, показанная в листинге 11, скорее всего, произошла по причине отсутствия необходимой схемы на подчиненном сервере, который не смог опознать атрибут sendmailMTAKey, и, как следствие, посчитал DN записи некорректным. Прежде чем можно будет возобновить репликацию, необходимо обновить схему подчиненного сервера.
Чтобы применить отклоненную запись, вы должны найти ошибку и устранить причины ее возникновения. Когда вы уверены, что отклоненная запись будет применена без ошибок, воспользуйтесь режимом slurpd one-shot mode, выполнив команду slurpd -r /path/to/rejection.rej -o. Параметр -r указывает slurpd прочесть указанный журнал репликации, а параметр -o переводит slurpd в режим one-shot mode, который означает, что по завершении обработки журнала slurpd закончит свою работу, а не перейдет в режим ожидания с целью добавления других записей (этот режим используется по умолчанию).
Если репликация не работает вовсе, лучше всего начать диагностику с главного сервера. Прежде всего, остановите процесс slurpd с помощью команды kill и измените какой-нибудь объект дерева каталога. Затем проверьте, увеличивается ли размер файла журнала репликации. Если размер файла не увеличивается, значит, главный сервер настроен неправильно. Далее, запустите slurpd с параметром командной строки -d 255. Данный режим отладки позволит отслеживать все действия slurpd, выполняемые при обработке журнала репликации. Ищите ошибки, в особенности, относящиеся к открытию файлов и контролю доступа.
Наконец, выполните на подчиненном сервере команду loglevel auth sync, чтобы проверить, не возникают ли какие-либо ошибки в процессе репликации (slapd ведет запись событий в журнал syslog от имени источника local4, поэтому, возможно вам придется добавить строку local4.* /var/log/slapd.log в файл /etc/syslog.conf).
Репликация LDAP Sync
Репликация посредством slurpd является простым, открытым решением, но имеет ряд недостатков. Остановка главного сервера с целью синхронизации подчиненного сервера в лучшем случае может доставить неудобства, а в худшем – повлиять на качество предоставляемых услуг. Архитектура slurpd на основе извещений также имеет ряд ограничений. Для своего времени slurpd работал достаточно хорошо, но необходимо было создать нечто лучшее. В документации RFC 4533 описывается процесс синхронизации контента LDAP, реализованный в OpenLDAP посредством механизма LDAP Sync, также известного как syncrepl.
Syncrepl является оверлейной программой, встраиваемой между ядром slapd и базой данных. Все операции записи в дерево каталога отслеживаются механизмом syncrepl; при этом не требуется использовать какую-либо отдельную службу. За исключением механизма репликации и поддержки ролей (этот вопрос будет рассмотрен далее) принципы работы syncrepl аналогичны работе slurpd. Попытки обновления реплики отклоняются, а клиент получает возвращаемую ссылку на главный сервер.
Служба syncrepl запускается на подчиненном сервере, который теперь называется получателем. Главный сервер выступает в роли provider. При репликации посредством syncrepl получатель подключается к источнику для получения обновлений каталога. В наиболее часто использующемся режиме работы, который называетсяrefreshOnly, получатель получает все измененные с момента последнего обновления записи, запрашивает маркер, содержащий сведения о последней синхронизации, и затем отключается. При следующем подключении этот маркер передается источнику, которые возвращает те записи, которые были изменены с момента последней синхронизации.
Другим режимом работы syncrepl является режим refreshAndPersist, работающий почти так же, как и refreshOnly, за исключением того, что получатель не отключается от источника после выполнения синхронизации, а продолжает получать все изменения, поддерживая подключение. Все изменения, произошедшие после первоначальной синхронизации, немедленно передаются от источника получателю.
Настройка syncrepl
В листинге 12 представлена конфигурация сервера-источника для обоих режимов работы syncrepl (refreshOnly и refreshAndPersist).
Листинг 12. Настройка репликации syncrepl на сервере-источнике
overlay syncprov syncprov-checkpoint 100 10 syncprov-sessionlog 100 |
Первая строка в листинге 12 включает возможность использования оверлейной программы syncprov. Оверлей должен настраиваться в отношении определенной базы данных, поэтому код в указанном листинге должен располагаться после настройки параметра database. Следующие две строки являются необязательными, однако повышают надежность. Строка syncprov-checkpoint 100 10 указывает серверу сохранять значения параметра contextCSN на жесткий диск каждые 100 операций записи или каждые 10 минут. Параметр contextCSN является частью упомянутого ранее маркера, помогающего серверу-получателю получать изменения, произошедшие с момента завершения предыдущей репликации. Строка syncprov-sessionlog 100 регистрирует все операции записи в журнале, хранящемся на жестком диске, что также помогает поддерживать цикл синхронизации.
Для получения дополнительной информации о настройке источника обратитесь к man-руководству slapo-syncprov(5).
В листинге 13 приведена настройка сервера-получателя, участвующего в двустороннем процессе репликации.
Листинг 13. Настройка репликации syncrepl в режиме refreshOnly на сервере-получателе
updateref ldap://masterserver.ertw.com syncrepl rid=1 provider=ldap://masterserver.ertw.com type=refreshOnly interval=00:01:00:00 searchbase="dc=ertw,dc=com" bindmethod=simple binddn="uid=replica1,dc=ertw,dc=com" credentials=replica1 |
Так же, как и для команды replica в случае синхронизации посредством slurpd, для команды syncrepl требуется указать ссылку updaterefи предоставить информацию о дереве каталога, которое вы пытаетесь реплицировать. Также необходимо предоставить учетные данные, которые будут использоваться для репликации. На этот раз учетные данные указываются на стороне получателя, а уровень доступа к источнику, предоставляемый для этих учетных данных, должен обеспечивать возможность чтения реплицируемой части дерева каталога. Все изменения базы данных на сервере-получателе выполняются от имени rootdn.
Параметры rid, provider, type и interval относятся к syncrepl. Параметр rid идентифицирует получателя на главном сервере. Получатель должен иметь уникальный идентификатор (ID), который может принимать значение от 1 до 999. Параметр provider является ссылкой LDAP в формате URI, указывающей на сервер-источник. Параметр typeуказывает, что синхронизация будет выполняться только в режиме refreshOnly, а параметр interval определяет периодичность синхронизации, равную одному часу. Значение параметра interval задается в формате DD:hh:mm:ss.
Запустите сервер-получатель с пустой базой данных, и его данные будут реплицироваться с сервером-источником каждый час.
Перевести синхронизацию в режим refreshAndPersist очень просто. Для этого удалите в листинге 13 строку interval и замените значение параметра type на refreshAndPersist.
Фильтрация syncrepl
Следует заметить, что вам не обязательно может потребоваться реплицировать дерево LDAP целиком. Для того чтобы выбрать только необходимые для репликации данные, вы можете использовать следующие команды.
Таблица 3. Команды для фильтрации трафика репликации
| Команда | Описание |
|---|---|
| searchbase | Различающееся имя, указывающее на узел дерева, с которого начнется репликация. При необходимости OpenLDAP заполнит нужные родительские узлы, чтобы обеспечить целостность дерева. |
| scope | Может принимать одно из значений: sub, one или base. Этот параметр определяет глубину репликации данных относительно начальной точки, указанной в параметре searchbase. Значением по умолчанию является sub; это значение охватывает узел searchbase и все его дочерние узлы. |
| filter | Фильтр поиска LDAP, такой как (objectClass=inetOrgPerson), определяющий набор записей для репликации. |
| attrs | Список атрибутов, которые будут извлечены из выбранных записей. |
Также как и остальные опции syncrepl, все вышеперечисленные параметры записываются в формате параметр=значение.
Постовой
Покупайте строительные материалы по оптимальной цене на строительном рынке.
Школа танцев Wanted-one.ru. Мы научим Вас танцевать так – как ни кто другой