


Распределение нагрузки между несколькими процессорами, дополненное различными методиками восстановления программного обеспечения, позволяет создать среду высокой готовности и улучшить совокупные показатели RAS (Reliability, Availability, and Serviceability – надёжность, готовность и удобство обслуживания) среды. К числу преимуществ такого подхода относится более быстрое восстановление после незапланированных выходов из строя, а также минимальное воздействие плановых отключений на конечных пользователей.
Чтобы получить максимум пользы от этой статьи, вы должны быть знакомы с Linux и основами сетевых технологий; также у вас должны быть настроены серверы Apache. В наших примерах используется стандартная установка SUSE Linux Enterprise Server 10 (SLES10), но знающие пользователи других дистрибутивов смогут адаптировать приведенные здесь методы и под них.
В этой статье продемонстрирован надежный комплекс Web-серверов Apache из 6 узлов Apache (хотя для описываемых ниже действий достаточно 3 узлов), а также 3 директоров Linux Virtual Server (LVS). Мы использовали 6 серверных узлов Apache, чтобы обеспечить более высокую пропускную способность и смоделировать более крупные системы. Представленную здесь архитектуру можно масштабировать для значительно большего количества директоров и серверов Apache, в зависимости от доступных ресурсов, хотя сами мы не пробовали более крупных конфигураций. На рисунке 1 показана реализация системы с применением Linux Virtual Server и компонентов linux-ha.org.
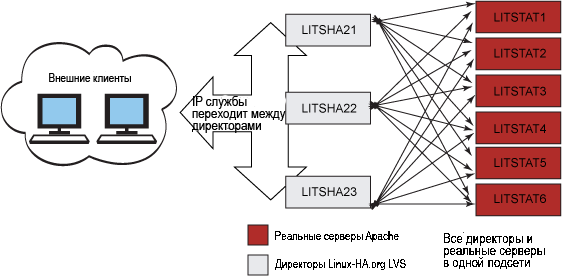
Рисунок 1. Linux Virtual Servers и Apache
Как можно увидеть на рисунке 1, внешние клиенты отправляют трафик на единый адрес IP, который может существовать на любой машине директора LVS. Машины директора выполняют активный мониторинг пула Web-серверов, по которым они распределяют работу.
Обратите внимание, что рабочая нагрузка движется с левой стороны рисунка 1 на правую сторону. Плавающий адрес этого кластера в любой заданный момент времени принадлежать одному из экземпляров директора LVS. Адрес сервиса можно менять вручную посредством графической конфигурационной утилиты или (чаще всего) он может изменяться автоматически, в зависимости от состояния директоров LVS. Если какой-либо из директоров становится неработоспособным (вследствие потери соединения, сбоя программного обеспечения и т.п.), адрес сервиса автоматически назначается доступному директору.
Плавающий адрес сервиса должен объединять два или более отдельных экземпляра оборудования, чтобы можно было продолжать работу в случае сбоя одной физической машины. В конфигурации, представленной в этой статье, каждый директор LVS может направлять пакеты на любой реальный Web-сервер Apache, независимо от места его физического расположения или близости к активному директору, предоставляющему плавающий адрес сервиса. В этой статье показано, как каждый из директоров LVS может выполнять активный мониторинг серверов Apache, чтобы запросы гарантированно отправлялись только на работающие серверы.
В такой конфигурации экспериментаторы успешно выводили из строя целые экземпляры Linux, и при этом обслуживание потребителей сервисов, связанных с плавающим адресом, не прекращалось (как правило, речь идет о Web-запросах http и https)
Новое в терминологии Linux Virtual Server
Директоры LVS: Директоры Linux Virtual Server – это системы, которые принимают произвольный входящий трафик и передают его любому количеству реальных серверов. После этого они получают ответ от реальных серверов и возвращают его клиентам, отправившим запрос. Директоры должны выполнять свою задачу прозрачно, чтобы клиенты не замечали, что фактически обработку нагрузки выполняют реальные серверы.
Сами директоры LVS должны иметь возможность передавать ресурсы (в частности, виртуальный адрес IP, по которому они принимают входящий трафик) друг другу, чтобы они не стали единичной точкой отказа. Директоры LVS выполняют передачу адреса IP с помощью компонента Heartbeat в составе LVS. Это позволяет каждому директору, на котором работает Heartbeat, гарантировать, что один и только один директор отвечает за обслуживание входящих запросов на обслуживание на адрес IP.
Кроме возможности передачи адреса IP службы, директоры должны иметь возможность мониторинга состояния реальных серверов, выполняющих фактическую обработку нагрузки. Директоры должны в любой момент времени знать, какие реальные серверы доступны для работы. Для того, чтобы контролировать реальные серверы, используется пакет mon.
Реальные серверы:Эти системы являются фактическими экземплярами Web-серверов, обеспечивающими высокую готовность сервиса. Если необходимо обеспечить высокую готовность, критически важно, чтобы реальных серверов, выполняющих обслуживание, было больше одного. В нашей среде использовалось 6 реальных серверов, но добавление большего числа не составляет никакого труда, если остальная инфраструктура LVS уже настроена.
В этой статье предполагается, что на всех реальных серверах работает Web-сервер Apache, хотя точно так же можно реализовать и другие сервисы (например, очень легко добавить сервис SSH в качестве дополнительного теста представленной здесь методологии).
В качестве реальных серверов использовались имеющиеся в наличии Web-серверы Apache, единственным отличием которых было то, что они были настроены на ответ таким образом, как если бы они имели плавающий IP-адрес директора LVS или виртуальное имя хоста, соответствующее плавающему IP-адресу. Это достигается изменением одной строки файла конфигурации Apache.
Вы можете повторить наш файл конфигурации, используя пакет программного обеспечения с полностью открытым исходным кодом, в который входят компоненты технологии Heartbeat, предоставленные linux-ha.org, и мониторинга сервера средствами mon и Apache. Как уже было отмечено, для тестирования нашей конфигурации мы использовали SUSE Linux Enterprise Server.
Все машины, использованные в нашем сценарии LVS, располагаются в одной подсети в конфигурации трансляции сетевых адресов (Network Address Translation, NAT). На сайте Linux Virtual Server приведены описания множества других сетевых топографий; мы выбрали NAT для простоты. Для обеспечения большей безопасности необходимо ограничить трафик через брандмауэры только трафиком на плавающий IP-адрес, который переходит между директорами LVS.
В комплекте Linux Virtual Server реализовано несколько методов построения прозрачной внутренней инфраструктуры высокой готовности. У каждого метода есть свои преимущества и недостатки. LVS-NAT работает на сервере директора, перехватывая входящие пакеты, адресованные на указанные в конфигурации порты, и динамически заменяя адрес назначения в заголовке пакета. Директор не обрабатывает данные, содержащиеся в самих пакетах, направляя их вместо этого на реальные серверы. Адрес назначения в пакетах заменяется адресом заданного реального сервера из кластера. После этого пакет передаётся в сеть для доставки на реальный сервер; при этом реальный сервер не видит, что что-то произошло. С точки зрения реального сервера он просто получает запрос напрямую из внешнего мира. После этого ответы реального сервера отправляются директору, где они снова переписываются так, что в качестве адреса отправителя устанавливается плавающий IP-адрес, указанный клиентом, и отправляются исходному клиенту.
Использование подхода LVS-NAT требует наличия на реальных серверах базовой функциональности TCP/IP. В других режимах работы LVS, а именно, в LVS-DR и LVS-Tun, требуются более сложные сетевые подходы. Основное преимущество выбора LVS-NAT состоит в том, что для настройки реальных серверов требуется минимум изменений конфигурации. Фактически самое сложное – это не забыть правильно установить параметры маршрутизации.
Шаг 1: Создание образов реальных серверов
Начните с создания пула экземпляров серверов Linux, на каждом из которых работает Web-сервер Apache, и проверки их работоспособности, указывая в браузере IP-адрес каждого реального сервера. Как правило, в стандартной установке настраивается мониторинг порта 80 на собственном IP-адресе (другими словами, на разных IP для каждого реального сервера).
После этого настройте Web-страницу по умолчанию на отображение статической страницы, содержащей название узла машины, обслуживающей эту страницу. Это поможет вам точно знать во время проведения испытаний, к какой машине вы подключаетесь.
В качестве меры предосторожности проверьте, что на этих системах отключено перенаправление IP, выполнив следующую команду:
# cat /proc/sys/net/ipv4/ip_forward
Если оно включено, выключите эту функцию, выполнив следующую команду:
# echo "0" >/proc/sys/net/ipv4/ip_forward
Простейшим способом проверки того, что каждый из реальных серверов настроен должным образом на мониторинг порта http (80), является использование внешней системы и выполнение сканирования. Для проверки того, что сервер ведет мониторинг порта, вы можете использовать утилиту nmap с какой-либо другой системы, подключенной к сети, в которой находятся ваши серверы.
Листинг 1. Использование nmap для проверки работы сервера
# nmap -P0 192.168.71.92Starting nmap 3.70 ( http://www.insecure.org/nmap/ ) at 2006-01-13 16:58 ESTInteresting ports on 192.168.71.92: (The 1656 ports scanned but not shown below are in state: closed) PORT STATE SERVICE 22/tcp open ssh 80/tcp filtered http 111/tcp open rpcbind 631/tcp open ipp
Нужно помнить, что некоторые организации не одобряют сканирования портов такими инструментами, как nmap: перед тем, как использовать его, убедитесь, что в вашей организации это разрешено.
Далее укажите в вашем браузере фактические IP-адреса каждого сервера для проверки того, что выводится нужная страница. После этого переходите к шагу 2.
Шаг 2: Установка и настройка директоров LVS
Теперь вы готовы к созданию трёх необходимых экземпляров директоров LVS. Если вы производите установку SUSE Linux Enterprise Server 10 с нуля для каждого из директоров LVS, не забудьте выбрать в ходе установки пакеты высокой готовности, относящиеся к heartbeat, ipvsadm и mon. Если система у вас уже установлена, вы всегда можете добавить эти пакеты с помощью инструмента управления пакетами, например, YAST. Настоятельно рекомендуется добавить каждый из реальных серверов в файл /etc/hosts. Это позволит избежать задержек, связанных с запросами DNS, при обработке входящих запросов.
На этом этапе нужно тщательно удостовериться, что каждый директор может отправить запрос и своевременно получить ответ от каждого из реальных серверов:
Листинг 2. Опрос реальных серверов
# ping -c 1 $REAL_SERVER_IP_1 # ping -c 1 $REAL_SERVER_IP_2# ping -c 1 $REAL_SERVER_IP_3 # ping -c 1 $REAL_SERVER_IP_4 # ping -c 1 $REAL_SERVER_IP_5 # ping -c 1 $REAL_SERVER_IP_6
После этого установите на сервер пакеты ipvsadm, Heartbeat и mon из инструмента управления пакетами. Помните, что Heartbeat будет использоваться для связи между директорами, а mon – каждым директором для получения информации о состоянии реальных серверов.
Шаг 3: Установка и настройка Heartbeat на директорах
Если вы ранее работали с LVS, имейте в виду, что настройка Heartbeat версии 2 на SLES10 отличается от настройки Heartbeat версии 1 на SLES9. Там, где в Heartbeat версии 1 использовались файлы (haresources, ha.cf и authkeys) , хранящиеся в директории /etc/ha.d/, в версии 2 используется информационная база кластера (Cluster Information Base, CIB), основанная на XML. Рекомендуемый подход к обновлению – использовать файл haresources для создания нового файла cib.xml. Типичное содержимое файла ha.cf показано в листинге 3.
Мы взяли файл ha.cf из системы SLES9 и добавили три последние строки (respawn, pingd и crm) в версию 2. Если у вас есть конфигурация от версии 1, вы можете сделать то же самое. Если вы используете эти инструкции для установки на новой системе, вы можете скопировать содержимое листинга 3 и изменить его в соответствии с вашей рабочей средой.
Листинг 3. Пример файла конфигурации /etc/ha.d/ha.cf
# Подключение к серверу syslog как устройство "daemon" use_logd on logfacility daemon # Перечень компонентов кластера (реальных серверов) node litsha22 node litsha23 node litsha21 # Отправка одного сигнала heartbeat каждую секунду keepalive 3 # Предупреждение об опаздывающих сигналах heartbeats warntime 5 # Объявляем узлы отключенными после 10 секунд deadtime 10 # Удержание ресурсов на "предпочтительных" узлах, необходимо для активого узла #auto_failback on # Узлы кластера связаны по сети heartbeat (.68.*) ucast eth1 192.168.68.201 ucast eth1 192.168.68.202 ucast eth1 192.168.68.203 # Восстановление после сбоя сети # Опрос узла по публичному интерфейсу по умолчанию # (-m) -> Для каждого узла добавляем <целое число> к значению # в CIB, * По умолчанию=1 # (-d) -> Как долго ждать отсутствия изменений перед обновлением # CIB измененным атрибутом # (-a) -> Название устанавливаемого атрибута узла, * по умолчанию=pingd respawn hacluster /usr/lib/heartbeat/pingd -m 100 -d 5s # Опрос маршрутизатора для мониторинга сети ethernet ping litrout71_vip #Включение функции версии 2 на кластерах с with > 2 узлов crm yes |
Для указания запускаемой и контролируемой программы используется директива respawn. Если программа завершает свою работу с кодом, отличным от 100, она будет автоматически запущена снова. В качестве первого параметра используется идентификатор пользователя, под которым будет запускаться программа, а в качестве второго – программа, которую нужно запускать. Параметр -m устанавливает атрибуту pingd значение, равное умноженному на 100 числу узлов, доступных для ping с текущей машины, а параметр -d определяет задержку в 5 секунд перед изменением атрибута pingd в CIB. Директива ping указывает узел PingNode для Heartbeat, а директива crm определяет, что Heartbeat должен работать как менеджер кластера, в стиле 1.x или 2.x, поддерживая более двух узлов.
Этот файл должен быть идентичным на всех трёх директорах. Критически важно установить на этот файл правильные права доступа, чтобы его смог прочитать демон hacluster. Если этого не сделать, в файл журнала будет выдана масса предупреждений, разобраться в которых будет очень сложно.
Для кластера Heartbeat стиля 1 файл haresources указывает название узла и сетевую информацию (плавающий IP, соответствующий интерфейс и широковещательная рассылка сообщений). Для нашего случая оставим файл без изменений:
litsha21 192.168.71.205/24/eth0/192.168.71.255
Этот файл будет использоваться только для создания файла cib.xml.
В файле authkeys указываются общий секретный ключ, позволяющий директорам связываться друг с другом. Общий секретный ключ – это обычный пароль, известный всем узлам heartbeat и используемый ими для связи друг с другом. Секретный ключ предотвращает вмешательство нежелательных лиц в работу серверных узлов heartbeat. Этот файл также оставляем неизменным:
auth 1
1 sha1 ca0e08148801f55794b23461eb4106db
В следующих шагах вы увидите, как преобразовать файл haresources версии 1 в новый формат конфигурации версии 2, в основе которого лежит XML (cib.xml). Несмотря на то, что для начала можно просто скопировать файл конфигурации, приведенный в листинге 4, настоятельно рекомендуется выполнить приведенные ниже действия, чтобы скорректировать конфигурацию в соответствии с вашей системой.
Чтобы преобразовать форматы файлов в XML-файл CIB (Cluster Information Base), который будет использоваться в системе, выполните следующие команды:
python /usr/lib64/heartbeat/haresources2cib.py /etc/ha.d/haresources > /var/lib/heartbeat/crm/test.xml
Будет создан и размещен в папке /var/lib/heartbeat/crm/test.xml файл конфигурации, похожий на приведенный в листинге 4.
Листинг 4. Пример файла CIB.xml
<cib admin_epoch="0" have_quorum="true" num_peers="3" cib_feature_revision="1.3" generated="true" ccm_transition="7" dc_uuid="114f3ad1-f18a-4bec-9f01-7ecc4d820f6c" epoch="280" num_updates="5205" cib-last-written="Tue Apr 3 16:03:33 2007"> <configuration> <crm_config> <cluster_property_set id="cib-bootstrap-options"> <attributes> <nvpair id="cib-bootstrap-options-symmetric_cluster" name="symmetric_cluster" value="true"/> <nvpair id="cib-bootstrap-options-no_quorum_policy" name="no_quorum_policy" value="stop"/> <nvpair id="cib-bootstrap-options-default_resource_stickiness" name="default_resource_stickiness" value="0"/> <nvpair id="cib-bootstrap-options-stonith_enabled" name="stonith_enabled" value="false"/> <nvpair id="cib-bootstrap-options-stop_orphan_resources" name="stop_orphan_resources" value="true"/> <nvpair id="cib-bootstrap-options-stop_orphan_actions" name="stop_orphan_actions" value="true"/> <nvpair id="cib-bootstrap-options-remove_after_stop" name="remove_after_stop" value="false"/> <nvpair id="cib-bootstrap-options-transition_idle_timeout" name="transition_idle_timeout" value="5min"/> <nvpair id="cib-bootstrap-options-is_managed_default" name="is_managed_default" value="true"/> <attributes> <cluster_property_set> <crm_config> <nodes> <node uname="litsha21" type="normal" id="01ca9c3e-8876-4db5-ba33-a25cd46b72b3"> <instance_attributes id="standby-01ca9c3e-8876-4db5-ba33-a25cd46b72b3"> <attributes> <nvpair name="standby" id="standby-01ca9c3e-8876-4db5-ba33-a25cd46b72b3" value="off"/> <attributes> <instance_attributes> <node> <node uname="litsha23" type="normal" id="dc9a784f-3325-4268-93af-96d2ab651eac"> <instance_attributes id="standby-dc9a784f-3325-4268-93af-96d2ab651eac"> <attributes> <nvpair name="standby" id="standby-dc9a784f-3325-4268-93af-96d2ab651eac" value="off"/> <attributes> <instance_attributes> <node> <node uname="litsha22" type="normal" id="114f3ad1-f18a-4bec-9f01-7ecc4d820f6c"> <instance_attributes id="standby-114f3ad1-f18a-4bec-9f01-7ecc4d820f6c"> <attributes> <nvpair name="standby" id="standby-114f3ad1-f18a-4bec-9f01-7ecc4d820f6c" value="off"/> <attributes> <instance_attributes> <node> <nodes> <resources> <primitive class="ocf" provider="heartbeat" type="IPaddr" id="IPaddr_1"> <operations> <op id="IPaddr_1_mon" interval="5s" name="monitor" timeout="5s"/> <operations> <instance_attributes id="IPaddr_1_inst_attr"> <attributes> <nvpair id="IPaddr_1_attr_0" name="ip" value="192.168.71.205"/> <nvpair id="IPaddr_1_attr_1" name="netmask" value="24"/> <nvpair id="IPaddr_1_attr_2" name="nic" value="eth0"/> <nvpair id="IPaddr_1_attr_3" name="broadcast" value="192.168.71.255"/> <attributes> <instance_attributes> <primitive> <resources> <constraints> <rsc_location id="rsc_location_IPaddr_1" rsc="IPaddr_1"> <rule id="prefered_location_IPaddr_1" score="200"> <expression attribute="#uname" id="prefered_location_IPaddr_1_expr" operation="eq" value="litsha21"/> <rule> <rsc_location> <rsc_location id="my_resource:connected" rsc="IPaddr_1"> <rule id="my_resource:connected:rule" score_attribute="pingd"> <expression id="my_resource:connected:expr:defined" attribute="pingd" operation="defined"/> <rule> <rsc_location> <constraints> <configuration> <cib> |
После создания файла конфигурации переместите файл test.xml в cib.xml, измените владельца на hacluster, а группу на haclient, и перезапустите процесс heartbeat.
Завершив конфигурирование heartbeat, установите автоматический запуск heartbeat при загрузке системы на каждом директоре. Чтобы сделать это, выполните на каждом директоре следующую команду (или эквивалентную ей для вашего дистрибутива):
# chkconfig heartbeat on
Перезапустите все директоры LVS и проверьте, запускаются ли при загрузке службы heartbeat. Остановив машину, которая владеет плавающим IP-адресом ресурса, вы можете увидеть, как другие образы директоров LVS в течение нескольких секунд устроят голосование и выбранный ими основной узел примет адрес на себя. Если вы снова включите остановленный ранее образ, машины снова проведут голосование между всеми узлами, в ходе которого плавающий IP-адрес ресурса может быть передан обратно. Весь процесс должен занимать всего несколько секунд.
Кроме того, в это время вы можете использовать графическую утилиту процесса heartbeat, hb_gui (см. рисунок 2), для переключения IP-адреса вручную в рамках кластера путём перевода различных узлов в активное состояние или состояние ожидания. Повторите эти действия несколько раз, отключая и включая различные активные и неактивные машины. Если выбрана приведенная выше политика конфигурирования, может быть объявлено голосование и хотя бы один узел будет доступен, плавающий IP-адрес ресурса будет оставаться рабочим. Во время испытания вы можете с помощью обычного эхо-тестирования проверить отсутствие потери пакетов. Когда вы закончите эксперименты, у вас должна сложиться уверенность в устойчивости вашей конфигурации. Перед тем, как продолжить, убедитесь, что разбираетесь в настройке высокой готовности плавающего IP ресурса.
Рисунок 2. Графическая утилита конфигурации процесса heartbeat, hb_gui
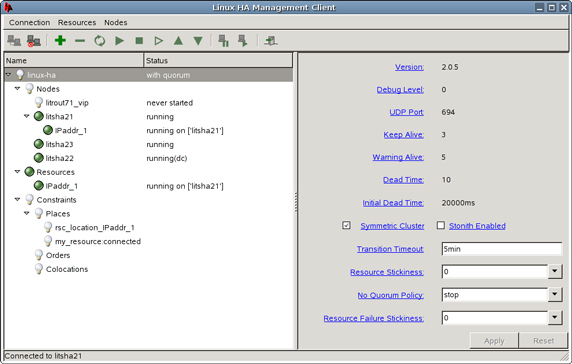
На рисунке 2 показано, как выглядит графическая консоль после входа в систему, на ней показаны управляемые ресурсы и связанные с ними параметры. Обратите внимание, что при первом запуске приложения вы должны войти в консоль hb_gui; учетная запись для входа будет зависеть от вашей системы.
Обратите внимание, что на рисунке 2 все узлы кластера, системы litsha2*, находятся в рабочем состоянии. Система litsha21 является активным узлом, что показано добавлением ресурса сразу после неё с отступом (IPaddr_1).
Кроме того, обратите внимание на выбранное значение параметра “No Quorum Policy” в “stop”. Это означает, что любой изолированный узел должен освободить все ресурсы, которые могли ему принадлежать. Такое решение подразумевает, что для создания кворума в любой момент времени должны быть активны как минимум два узла heartbeat (другими словами, большинство голосов). Даже если активен один узел и 100% работающий узел прервет соединение с клиентскими системами из-за сбоя сети, если обе неактивных системы отключатся одновременно, то ресурс будет освобожден добровольно.
Шаг 4: Создание правил LVS с помощью команды ipvsadm
На следующем шаге мы сосредоточимся на плавающем IP-адресе. Поскольку LVS должен быть прозрачным для клиентов удалённых браузеров, все запросы должны направляться через директоры и передаваться одному из реальных серверов. После этого все необходимые результаты возвращаются директорам, которые направляют ответ клиенту, инициировавшему запрос Web-страницы.
Чтобы организовать такой поток запросов и ответов, для начала нужно настроить все директоры LVS, включив на них пересылку пакетов IP (таким образом разрешив передачу запросов на реальные серверы), выполнением следующих команд:
# echo "1" >/proc/sys/net/ipv4/ip_forward
# cat /proc/sys/net/ipv4/ip_forward
Если всё прошло удачно, то вторая команда выведет “1″ на терминал. Для того чтобы эта настройка сохранялась постоянно, добавьте
'' IP_FORWARD="yes"
в файл /etc/sysconfig/sysctl.
Далее, чтобы сообщить директорам о необходимости перенаправления входящих запросов HTTP на плавающий IP-адрес высокой готовности реальным серверам, выполните команду ipvsadm .
Сначала очистите старые таблицы ipvsadm:
# /sbin/ipvsadm -C
Перед тем как настроить новые таблицы, вам нужно решить, какой тип распределения нагрузки будут использовать директоры LVS. При получении запроса от клиента директор назначает клиенту реальный сервер на основе “графика”; режим составления этого графика устанавливается с помощью команды ipvsadm. Доступны следующие режимы:
- Круговое обслуживание (RR): Новые входящие соединения будут назначаться каждому реальному серверу по очереди.
- Взвешенное круговое обслуживание (WRR) : Режим RR с дополнительным весовым коэффициентом, компенсирующим различие мощностей реальных серверов, таких как процессоров, памяти и т.п.
- По наименьшему числу соединений (LC): Новые соединения передаются к реальному серверу с минимальным числом соединений. Это не обязательно менее загруженный сервер, но это шаг именно в этом направлении.
- По наименьшему числу соединений с весовыми коэффициентами (WLC): Режим LC с взвешиванием.
Для целей тестирования разумно использовать график RR, поскольку его легко проверить. Для проверки правильности функционирования в ходе тестирования вы можете добавить режимы WRR и LC. В приведенных здесь примерах предполагается использование режима RR и его вариаций.
После этого создайте сценарий, разрешающий сервису ipvsadm выполнять пересылку пакетов на реальный сервер и поместить его копию на каждый директор LVS. Этот сценарий не нужен, если позже, в конфигурации mon, выполняется автоматический мониторинг реальных серверов, но он помогает до этого, при тестировании компонента ipvsadm. Не забудьте перед запуском этого сценария повторно проверить правильность сетевых настроек и соединения http/https с каждым из реальных серверов.
Листинг 5. Файл HA_CONFIG.sh
#!/bin/sh # Виртуальный адрес на директоре, который действует как адрес кластера VIRTUAL_CLUSTER_ADDRESS=192.168.71.205 REAL_SERVER_IP_1=192.168.71.220 REAL_SERVER_IP_2=192.168.71.150 REAL_SERVER_IP_3=192.168.71.121 REAL_SERVER_IP_4=192.168.71.145 REAL_SERVER_IP_5=192.168.71.185 REAL_SERVER_IP_6=192.168.71.186 # установка ip_forward ON для директора vs-nat (1 включено, 0 выключено). cat /proc/sys/net/ipv4/ip_forward echo "1" >/proc/sys/net/ipv4/ip_forward # директоры действуют как шлюзы для реальных серверов # Выключение редиректов icmp (1 включено, 0 выключено), # если реальные серверы недостаточно умны и не используют # директоры в качестве шлюза! echo "0" >/proc/sys/net/ipv4/conf/all/send_redirects echo "0" >/proc/sys/net/ipv4/conf/default/send_redirects echo "0" >/proc/sys/net/ipv4/conf/eth0/send_redirects # Очистка таблиц ipvsadm (больше безопасности, чем сожаления) /sbin/ipvsadm -C # Устанавливаем службу LVS как ipvsadm для соединений HTTP и HTTPS с # графиком RR /sbin/ipvsadm -A -t $VIRTUAL_CLUSTER_ADDRESS:http -s rr /sbin/ipvsadm -A -t $VIRTUAL_CLUSTER_ADDRESS:https -s rr # Первый реальный сервер # Перенаправление HTTP на REAL_SERVER_IP_1 с LVS-NAT (-m), и весом=1 /sbin/ipvsadm -a -t $VIRTUAL_CLUSTER_ADDRESS:http -r $REAL_SERVER_IP_1:http -m -w 1 /sbin/ipvsadm -a -t $VIRTUAL_CLUSTER_ADDRESS:https -r $REAL_SERVER_IP_1:https -m -w 1 # Второй реальный сервер # Перенаправление HTTP на REAL_SERVER_IP_2 с LVS-NAT (-m), и весом=1 /sbin/ipvsadm -a -t $VIRTUAL_CLUSTER_ADDRESS:http -r $REAL_SERVER_IP_2:http -m -w 1 /sbin/ipvsadm -a -t $VIRTUAL_CLUSTER_ADDRESS:https -r $REAL_SERVER_IP_2:https -m -w 1 # Третий реальный сервер # Перенаправление HTTP на REAL_SERVER_IP_3 с LVS-NAT (-m), и весом=1 /sbin/ipvsadm -a -t $VIRTUAL_CLUSTER_ADDRESS:http -r $REAL_SERVER_IP_3:http -m -w 1 /sbin/ipvsadm -a -t $VIRTUAL_CLUSTER_ADDRESS:https -r $REAL_SERVER_IP_3:https -m -w 1 # Четвертый реальный сервер # Перенаправление HTTP на REAL_SERVER_IP_4 с LVS-NAT (-m), и весом=1 /sbin/ipvsadm -a -t $VIRTUAL_CLUSTER_ADDRESS:http -r $REAL_SERVER_IP_4:http -m -w 1 /sbin/ipvsadm -a -t $VIRTUAL_CLUSTER_ADDRESS:https -r $REAL_SERVER_IP_4:https -m -w 1 # Пятый реальный сервер # Перенаправление HTTP на REAL_SERVER_IP_5 с LVS-NAT (-m), и весом=1 /sbin/ipvsadm -a -t $VIRTUAL_CLUSTER_ADDRESS:http -r $REAL_SERVER_IP_5:http -m -w 1 /sbin/ipvsadm -a -t $VIRTUAL_CLUSTER_ADDRESS:https -r $REAL_SERVER_IP_5:https -m -w 1 # Шестой реальный сервер # Перенаправление HTTP на REAL_SERVER_IP_6 с LVS-NAT (-m), и весом=1 /sbin/ipvsadm -a -t $VIRTUAL_CLUSTER_ADDRESS:http -r $REAL_SERVER_IP_6:http -m -w 1 /sbin/ipvsadm -a -t $VIRTUAL_CLUSTER_ADDRESS:https -r $REAL_SERVER_IP_6:https -m -w 1 # Выводим новую таблицу ipvsadm для проверки echo "NEW IPVSADM TABLE:" /sbin/ipvsadm |
Как вы можете увидеть в листинге 5, сценарий просто включает службы ipvsadm, после чего запросы Web и SSL одинаковым образом перенаправляются каждому из отдельных реальных серверов. Мы использовали параметр -m для указания режима NAT, а также присваиваем каждому реальному серверу одинаковый вес 1 (-w 1). Указание веса при использовании обычного графика кругового обслуживания не требуется (поскольку по умолчанию всегда назначается вес 1). Параметр представлен на тот случай, если вы захотите использовать взвешенное круговое обслуживание. Для этого нужно заменить rr на wrr в двух последующих строках под комментарием об использовании кругового обслуживания, и, конечно, не забудьте скорректировать веса соответствующим образом. Более подробную информацию о различных графиках можно найти на странице man по теме ipvsadm.Теперь вы настроили все директоры на обработку входящих Web- и SSL-запросов на плавающий IP-адрес сервиса и передачи заданий на реальные серверы. Однако для того, чтобы получить трафик от реальных серверов и выполнить обратную обработку перед возвращением ответа клиенту, отправившему запрос, необходимо изменить ряд сетевых настроек директоров. Это необходимо вследствие реализации директоров LVS и реальных серверов в плоской сетевой топологии (имеется в виду, что все они находятся в одной подсети). Для того чтобы направить трафик ответа Apache через директоры, а не напрямую, нам нужно выполнить следующие действия:
echo "0" > /proc/sys/net/ipv4/conf/all/send_redirects
echo "0" > /proc/sys/net/ipv4/conf/default/send_redirects
echo "0" > /proc/sys/net/ipv4/conf/eth0/send_redirects
Это было сделано для того, чтобы не допустить попытки активного директора LVS установить короткий путь TCP/IP напрямую между реальным сервером и плавающим IP сервиса (поскольку они находятся в одной подсети). Обычно используется переадресация, поскольку она повышает производительность путём отбрасывания ненужных посредников сетевых соединений. Но в этом случае не получится выполнить исправление пакетов в исходящем трафике, как это необходимо для обеспечения прозрачности для клиента. На самом деле, если на директоре LVS не отключить переадресацию, трафик, отправляемый напрямую от реального сервера клиенту, будет выглядеть для клиента как незапрошенный сетевой ответ и будет отклонен.
Сейчас самое время установить маршрут по умолчанию для каждого из реальных серверов на плавающий IP-адрес сервиса, что гарантирует, что все ответы будут передаваться обратно директору для исправления пакетов, после чего они будут направляться клиенту, пославшему запрос.
После того, как на директорах отключена переадресация и реальные серверы настроены на маршрутизацию всего трафика через плавающий IP сервиса, вы можете переходить к тестированию среды высокой готовности LVS. Чтобы проверить проделанную на данный момент работу, укажите в браузере на удалённом клиенте плавающий адрес службы директоров LVS.
Для тестирования в лаборатории мы использовали браузер на базе Gecko (Mozilla), хотя подойдёт любой другой браузер. Для того чтобы проверить успешность установки, отключите кэширование в браузере и нажмите кнопку обновления несколько раз. При каждом обновлении вы увидите одну из Web-страниц, настроенных на реальном сервере. Если вы используете график RR, вы будете наблюдать циклически страницы всех реальных серверов по очереди.
Вы думаете, что теперь нужно настроить автоматический запуск конфигурации LVS при запуске? Не торопитесь! Осталось выполнить ещё один шаг (шаг 5) для активного мониторинга реальных серверов (при этом создаётся динамический список узлов Apache, доступных для обслуживания запросов).
Шаг 5: Установка и настройка mon на директорах LVS
До сих пор мы устанавливали IP-адрес сервиса высокой готовности и связывали его с пулом экземпляров реальных серверов. Однако никогда не нужно доверять работоспособности отдельного сервера Apache в произвольный момент времени. Если в режиме RR какой-либо из реальных серверов отключается или не отвечает своевременно на сетевой трафик, каждый шестой запрос HTTP будет приводить к отказу!
Поэтому необходимо реализовать мониторинг реальных серверов на каждом директоре LVS, чтобы динамически добавлять их в рабочий пул и удалять их из него. Для этой цели отлично подходит ещё один хорошо известный пакет с открытым исходным кодом под названием mon.
ешение mon обычно используется для мониторинга реальных узлов LVS. Mon относительно прост в настройке и очень хорошо расширяем для людей, знакомых с написанием сценариев командного процессора. Для организации работы требуется выполнить три основных шага: установка, настройка службы мониторинга и создание уведомлений. Установите mon с помощью инструмента управления пакетами. По завершении установки вам остаётся только подкорректировать конфигурацию мониторинга и создать несколько сценариев предупреждения. Сценарии предупреждения срабатывают в случаях, когда мониторы определяют отключение или включение реального сервера.
Обратите внимание, что в системах heartbeat v2 мониторинг реальных серверов можно выполнять посредством назначения всех реальных серверов ресурсами сервиса. Кроме того, вы можете использовать пакет Heartbeat ldirectord.
По умолчанию mon поставляется с несколькими готовыми к использованию механизмами. Мы изменили пример файла конфигурации /etc/mon.cf на использование службы HTTP.
Убедитесь, что пути в заголовке файла конфигурации mon верны. SLES10 является 64-разрядной версией Linux, а пример конфигурации, входящий в комплект поставки, был создан для систем по умолчанию (31- или 32-разрядных). В файле конфигурации предполагалось, что предупреждения и мониторы находятся в папке /usr/lib, что неверно для нашей конкретной системы. Мы изменили следующие параметры:
alertdir = /usr/lib64/mon/alert.d
mondir = /usr/lib64/mon/mon.d
Как вы могли заметить, мы просто заменили lib на lib64. В вашем дистрибутиве, возможно, такого изменения делать не нужно.
Следующее изменение файла конфигурации состоит в указании перечня контролируемых реальных серверов. Это делается посредством шести директив:
Листинг 6. Указание контролируемых реальных серверов
hostgroup litstat1 192.168.71.220 # реальный сервер 1 hostgroup litstat2 192.168.71.150 hostgroup litstat3 192.168.71.121 hostgroup litstat4 192.168.71.145 hostgroup litstat5 192.168.71.185 hostgroup litstat6 192.168.71.186 # реальный сервер 6 |
Если вы желаете добавить другие реальные серверы, просто добавьте сюда строчки.
После того как все определения будут сделаны, вам нужно сообщить mon, каким образом будет обнаруживаться сбой и что делать в случае сбоя. Для этого добавьте следующие секции мониторов (по одной для каждого реального сервера). После этого вам нужно разместить файлы конфигурации mon и предупреждения на каждый узел LVS heartbeat, включив на каждом узле heartbeat независимый мониторинг всех реальных серверов.
Листинг 7. Файл /etc/mon/mon.cf
# # глобальные параметры # cfbasedir = /etc/mon alertdir = /usr/lib64/mon/alert.d mondir = /usr/lib64/mon/mon.d statedir = /var/lib/mon logdir = /var/log maxprocs = 20 histlength = 100 historicfile = mon_history.log randstart = 60s # # тип аутентификации: # getpwnam стандартный passwd Unix, не скрытые пароли # shadow Скрытые пароли Unix (не реализовано) # userfile файл пользователя "mon" # authtype = getpwnam # # протоколирование простоев,З при необходимости снимите комментарий # Если сервер работает, не забывайте подать команду сброса # при изменении этого параметра # #dtlogfile = downtime.log dtlogging = yes # # NB: записи hostgroup и watch заканчиваются пустой строкой (или концом # файла). Не забывайте про пустые строки между ними. # # # определение группы (названия узлов или адреса IP) # пример: # # hostgroup серверы www mail pop server4 server5 # # Для простоты мы контроллируем каждый сервер как отдельную группу, поэтому # указывает для каждого узла только название и адрес ip. hostgroup litstat1 192.168.71.220 hostgroup litstat2 192.168.71.150 hostgroup litstat3 192.168.71.121 hostgroup litstat4 192.168.71.145 hostgroup litstat5 192.168.71.185 hostgroup litstat6 192.168.71.186 # # Теперь устаавливаем одинаковые опредедения watch для каждой группы. Они могут # быть настроены на каждый сервер по-отдельности, но мы сделали однородную # конфигурацию, соответствующую однородной конфигурации LVS. # watch litstat1 service http description http check servers interval 6s monitor http.monitor -p 80 -u /index.html allow_empty_group period wd {Mon-Sun} alert dowem.down.alert -h upalert dowem.up.alert -h alertevery 600s alertafter 1 watch litstat2 service http description http check servers interval 6s monitor http.monitor -p 80 -u /index.html allow_empty_group period wd {Mon-Sun} alert dowem.down.alert -h upalert dowem.up.alert -h alertevery 600s alertafter 1 watch litstat3 service http description http check servers interval 6s monitor http.monitor -p 80 -u /index.html allow_empty_group period wd {Mon-Sun} alert dowem.down.alert -h upalert dowem.up.alert -h alertevery 600s alertafter 1 watch litstat4 service http description http check servers interval 6s monitor http.monitor -p 80 -u /index.html allow_empty_group period wd {Mon-Sun} alert dowem.down.alert -h upalert dowem.up.alert -h alertevery 600s alertafter 1 watch litstat5 service http description http check servers interval 6s monitor http.monitor -p 80 -u /index.html allow_empty_group period wd {Mon-Sun} alert dowem.down.alert -h upalert dowem.up.alert -h alertevery 600s alertafter 1 watch litstat6 service http description http check servers interval 6s monitor http.monitor -p 80 -u /index.html allow_empty_group period wd {Mon-Sun} alert dowem.down.alert -h upalert dowem.up.alert -h alertevery 600s alertafter 1 |
В листинге 7 мы сообщаем mon о необходимости использования http.monitor, который поставляется с mon по умолчанию. Кроме того, указывается использование порта 80. В листинге 7 также указана страница, которую необходимо запрашивать; возможно, вы предпочтёте передавать в качестве доказательства работы сервера сегмент html меньшего размера, чем сложная HTML-страница по умолчанию вашего Web-сервера.
В строках alert и upalert вызываются сценарии, которые должны быть размещены в папку alertdir , указанную в начале файла конфигурации. Как правило, в качестве директории используется какая-либо из директорий по умолчанию дистрибутива, например “/usr/lib64/mon/alert.d”. Предупреждения сообщают LVS о необходимости добавления и удаления серверов Apache из списка доступных (вызовом команды ipvsadm, как мы скоро увидим).
Когда один из реальных серверов не проходит тест http, mon автоматически выполняет команду dowem.down.alert с несколькими аргументами. И наоборот, когда мониторы определяют, что реальный сервер включился, процесс mon автоматически выполняет dowem.up.alert с несколькими аргументами. Вы можете изменять названия сценариев предупреждений в соответствии с потребностями вашей системы.
Сохраните этот файл и создайте предупреждения (с помощью простого сценария bash) в папке alertdir. В листинге 8 показан сценарий bash, вызываемый mon при восстановлении соединения с реальным сервером.
Листинг 8. Пример предупреждения: появилось соединение
#! /bin/bash # После аргумента h указывается название интересующего узла # мы пропускаем все параметры, кроме -h, так как они нас не интересуют REALSERVER=192.168.71.205 while [ $1 != "-h" ] ; do shift done ADDHOST=$2 # Для службы HTTP /sbin/ipvsadm -a -t $REALSERVER:http -r $ADDHOST:http -m -w 1 # Для службы HTTPS /sbin/ipvsadm -a -t $REALSERVER:https -r $ADDHOST:https -m -w 1 |
В листинге 9 показан сценарий bash, вызываемый mon при потере соединения с реальным сервером.
Листинг 9. Пример предупреждения: потеря соединения
#! /bin/bash # После аргумента h указывается название интересующего узла # мы пропускаем все параметры, кроме -h, так как они нас не интересуют REALSERVER=192.168.71.205 while [ $1 != "-h" ] ; do shift done BADHOST=$2 # Для службы HTTP /sbin/ipvsadm -d -t $REALSERVER:http -r $BADHOST # Для службы HTTPS /sbin/ipvsadm -d -t $REALSERVER:https -r $BADHOST |
Оба этих сценария используют инструмент командной строки ipvsadm для динамического добавления и удаления реальных серверов из таблиц LVS. Обратите внимание, что эти сценарии далеки от совершенства. Тогда как mon контролирует только готовность порта http для простых запросов Web, показанная здесь архитектура не защищена от ситуаций, когда заданный реальный сервер будет исправно работать для запросов http, но не для запросов SSL. В этом случае мы не сможем удалить отказавший реальный сервер из списка кандидатов https. Конечно же, это решается просто путём создания более продвинутых предупреждений для каждого типа Web-запросов, с добавлением второй монитор https для каждого реального сервера в файле конфигурации mon. Оставим это упражнение для читателя.
Чтобы убедиться в том, что мониторинг функционирует, включите и выключите процесс Apache последовательно на каждом сервере, наблюдая реакцию на эти события на директорах. Только после того, как вы убедитесь в правильности мониторинга всех реальных серверов, вы можете использовать команду chkconfig для того, чтобы убедиться, что процесс mon запускается автоматически во время загрузки системы Мы использовали команду chkconfig mon on, но она может изменяться в зависимости от используемого вами дистрибутива.
Установив последний элемент, мы закончили задачу построения кросс-системной инфраструктуры Web-серверов высокой готовности. Конечно же, вы можете захотеть выполнить дополнительные действия. Например, вы можете захотеть получать уведомления о том, что не работает мониторинг самого демона mon (мониторинг mon может выполнять проект heartbeat), но базовый фундамент мы уже заложили.
Существует множество причин, по которым активный узел может перестать функционировать должным образом в кластере высокой готовности, нарочно или непреднамеренно. Узел может потерять сетевое соединение с другими узлами, может быть остановлен процесс heartbeat, может произойти какое-нибудь стихийное бедствие, и так далее. Чтобы умышленно вывести из строя активный узел, вы можете остановить этот узел или перевести его в режим ожидания с помощью команды hb_gui (корректная остановка). Если вы хотите проверить устойчивость среды, вы можете действовать более агрессивно (выдерните вилку!).
Индикаторы и аварийное переключение
Для администратора, ответственного за настройку системы высокой готовности Linux heartbeat, существует два типа индикаторов журнала. Файлы журналов изменяются в зависимости от того, является ли система получателем плавающего IP-адреса ресурса. Данные журнала компонентов кластера, не получивших плавающего IP-адреса ресурса, выглядят примерно следующим образом:
Листинг 10. Файл журнала для остальных серверов
litsha21:~ # cat /var/log/messages Jan 16 12:00:20 litsha21 heartbeat: [3057]: WARN: node litsha23: is dead Jan 16 12:00:21 litsha21 cib: [3065]: info: mem_handle_event: Got an event OC_EV_MS_NOT_PRIMARY from ccm Jan 16 12:00:21 litsha21 cib: [3065]: info: mem_handle_event: instance=13, nodes=3, new=1, lost=0, n_idx=0, new_idx=3, old_idx=6 Jan 16 12:00:21 litsha21 crmd: [3069]: info: mem_handle_event: Got an event OC_EV_MS_NOT_PRIMARY from ccm Jan 16 12:00:21 litsha21 crmd: [3069]: info: mem_handle_event: instance=13, nodes=3, new=1, lost=0, n_idx=0, new_idx=3, old_idx=6 Jan 16 12:00:21 litsha21 crmd: [3069]: info: crmd_ccm_msg_callback:callbacks.c Quorum lost after event=NOT PRIMARY (id=13) Jan 16 12:00:21 litsha21 heartbeat: [3057]: info: Link litsha23:eth1 dead. Jan 16 12:00:38 litsha21 ccm: [3064]: debug: quorum plugin: majority Jan 16 12:00:38 litsha21 ccm: [3064]: debug: cluster:linux-ha, member_count=2, member_quorum_votes=200 Jan 16 12:00:38 litsha21 ccm: [3064]: debug: total_node_count=3, total_quorum_votes=300 .................. Сокращено .................. Jan 16 12:00:40 litsha21 crmd: [3069]: info: update_dc:utils.c Set DC to litsha21 (1.0.6) Jan 16 12:00:41 litsha21 crmd: [3069]: info: do_state_transition:fsa.c litsha21: State transition S_INTEGRATION -> S_FINALIZE_JOIN [ input=I_INTEGRATED cause=C_FSA_INTERNAL origin=check_join_state ] Jan 16 12:00:41 litsha21 crmd: [3069]: info: do_state_transition:fsa.c All 2 cluster nodes responded to the join offer. Jan 16 12:00:41 litsha21 crmd: [3069]: info: update_attrd:join_dc.c Connecting to attrd... Jan 16 12:00:41 litsha21 cib: [3065]: info: sync_our_cib:messages.c Syncing CIB to all peers Jan 16 12:00:41 litsha21 attrd: [3068]: info: attrd_local_callback:attrd.c Sending full refresh .................. Сокращено .................. Jan 16 12:00:43 litsha21 pengine: [3112]: info: unpack_nodes:unpack.c Node litsha21 is in standby-mode Jan 16 12:00:43 litsha21 pengine: [3112]: info: determine_online_status:unpack.c Node litsha21 is online Jan 16 12:00:43 litsha21 pengine: [3112]: info: determine_online_status:unpack.c Node litsha22 is online Jan 16 12:00:43 litsha21 pengine: [3112]: info: IPaddr_1 (heartbeat::ocf:IPaddr): Stopped Jan 16 12:00:43 litsha21 pengine: [3112]: notice: StartRsc:native.c litsha22 Start IPaddr_1 Jan 16 12:00:43 litsha21 pengine: [3112]: notice: Recurring:native.c litsha22 IPaddr_1_monitor_5000 Jan 16 12:00:43 litsha21 pengine: [3112]: notice: stage8:stages.c Created transition graph 0. .................. Сокращено .................. Jan 16 12:00:46 litsha21 mgmtd: [3070]: debug: update cib finished Jan 16 12:00:46 litsha21 crmd: [3069]: info: do_state_transition:fsa.c litsha21: State transition S_TRANSITION_ENGINE -> S_IDLE [ input=I_TE_SUCCESS cause=C_IPC_MESSAGE origin=do_msg_route ] Jan 16 12:00:46 litsha21 cib: [3118]: info: write_cib_contents:io.c Wrote version 0.53.593 of the CIB to disk (digest: 83b00c386e8b67c42d033a4141aaef90) |
Как видно из листинга 10, было инициировано переключение и имеется достаточное количество участников для голосования. Было произведено голосование и была продолжена нормальная работа без необходимости принятия дальнейших действий.
В отличие от этого, результаты компонентов кластера, получивших плавающий IP-адрес ресурса, имеют следующий вид:
Листинг 11. Файл журнала владельца ресурсаr
litsha22:~ # cat /var/log/messages Jan 16 12:00:06 litsha22 syslog-ng[1276]: STATS: dropped 0 Jan 16 12:01:51 litsha22 heartbeat: [3892]: WARN: node litsha23: is dead Jan 16 12:01:51 litsha22 heartbeat: [3892]: info: Link litsha23:eth1 dead. Jan 16 12:01:51 litsha22 cib: [3900]: info: mem_handle_event: Got an event OC_EV_MS_NOT_PRIMARY from ccm Jan 16 12:01:51 litsha22 cib: [3900]: info: mem_handle_event: instance=13, nodes=3, new=3, lost=0, n_idx=0, new_idx=0, old_idx=6 Jan 16 12:01:51 litsha22 crmd: [3904]: info: mem_handle_event: Got an event OC_EV_MS_NOT_PRIMARY from ccm Jan 16 12:01:51 litsha22 crmd: [3904]: info: mem_handle_event: instance=13, nodes=3, new=3, lost=0, n_idx=0, new_idx=0, old_idx=6 Jan 16 12:01:51 litsha22 crmd: [3904]: info: crmd_ccm_msg_callback:callbacks.c Quorum lost after event=NOT PRIMARY (id=13) Jan 16 12:02:09 litsha22 ccm: [3899]: debug: quorum plugin: majority Jan 16 12:02:09 litsha22 crmd: [3904]: info: do_election_count_vote:election.c Election check: vote from litsha21 Jan 16 12:02:09 litsha22 ccm: [3899]: debug: cluster:linux-ha, member_count=2, member_quorum_votes=200 Jan 16 12:02:09 litsha22 ccm: [3899]: debug: total_node_count=3, total_quorum_votes=300 Jan 16 12:02:09 litsha22 cib: [3900]: info: mem_handle_event: Got an event OC_EV_MS_INVALID from ccm Jan 16 12:02:09 litsha22 cib: [3900]: info: mem_handle_event: no mbr_track info Jan 16 12:02:09 litsha22 cib: [3900]: info: mem_handle_event: Got an event OC_EV_MS_NEW_MEMBERSHIP from ccm Jan 16 12:02:09 litsha22 cib: [3900]: info: mem_handle_event: instance=14, nodes=2, new=0, lost=1, n_idx=0, new_idx=2, old_idx=5 Jan 16 12:02:09 litsha22 cib: [3900]: info: cib_ccm_msg_callback:callbacks.c LOST: litsha23 Jan 16 12:02:09 litsha22 cib: [3900]: info: cib_ccm_msg_callback:callbacks.c PEER: litsha21 Jan 16 12:02:09 litsha22 cib: [3900]: info: cib_ccm_msg_callback:callbacks.c PEER: litsha22 .................. Сокращено .................. Jan 16 12:02:12 litsha22 crmd: [3904]: info: update_dc:utils.c Set DC to litsha21 (1.0.6) Jan 16 12:02:12 litsha22 crmd: [3904]: info: do_state_transition:fsa.c litsha22: State transition S_PENDING -> S_NOT_DC [ input=I_NOT_DC cause=C_HA_MESSAGE origin=do_cl_join_finalize_respond ] Jan 16 12:02:12 litsha22 cib: [3900]: info: cib_diff_notify:notify.c Update (client: 3069, call:25): 0.52.585 -> 0.52.586 (ok) .................. Сокращено .................. Jan 16 12:02:14 litsha22 IPaddr[3998]: INFO: /sbin/ifconfig eth0:0 192.168.71.205 netmask 255.255.255.0 broadcast 192.168.71.255 Jan 16 12:02:14 litsha22 IPaddr[3998]: INFO: Sending Gratuitous Arp for 192.168.71.205 on eth0:0 [eth0] Jan 16 12:02:14 litsha22 IPaddr[3998]: INFO: /usr/lib64/heartbeat/send_arp -i 500 -r 10 -p /var/run/heartbeat/rsctmp/send_arp/send_arp-192.168.71.205 eth0 192.168.71.205 auto 192.168.71.205 ffffffffffff Jan 16 12:02:14 litsha22 crmd: [3904]: info: process_lrm_event:lrm.c LRM operation (3) start_0 on IPaddr_1 complete Jan 16 12:02:14 litsha22 kernel: send_arp uses obsolete (PF_INET,SOCK_PACKET) Jan 16 12:02:14 litsha22 kernel: klogd 1.4.1, ---------- state change ---------- Jan 16 12:02:14 litsha22 kernel: NET: Registered protocol family 17 Jan 16 12:02:15 litsha22 crmd: [3904]: info: do_lrm_rsc_op:lrm.c Performing op monitor on IPaddr_1 (interval=5000ms, key=0:f9d962f0-4ed6-462d-a28d-e27b6532884c) Jan 16 12:02:15 litsha22 cib: [3900]: info: cib_diff_notify:notify.c Update (client: 3904, call:18): 0.53.591 -> 0.53.592 (ok) Jan 16 12:02:15 litsha22 mgmtd: [3905]: debug: update cib finished |
Как показано в листинге 11, в файле /var/log/messages записано, что узел получил плавающий адрес ресурса. В строке ifconfig показано, что было динамически создано устройство eth0:0, выполняющее обслуживание.
И как видно из листинга 11, было инициировано переключение и имеется достаточное количество участников для голосования. Было проведено голосование, после чего был выполнена команда ifconfig, требующая освободить плавающий IP-адрес.
В качестве дополнительного средства сигнализации сбоя, вы можете войти на любой компонент кластера и выполнить команду hb_gui . С помощью этого метода вы можете визуально определить, какая система владеет плавающим ресурсом.
И, наконец, статья не будет полной без иллюстрации примера файла журнала в случае отсутствия кворума. Если какой-либо узел не может соединиться с двумя другими узлами, он теряет кворум (поскольку при наличии трёх участников большинство составляет 2/3). В этом случае узел понимает, что он потерял кворум и запускает обработчик правила на случай потери кворума. В листинге 12 показан пример файла журнала для такого события. В случае, если кворум потерян, в журнал будет занесена соответствующая запись. Узел кластера, на котором появилась такая запись, освободит занимаемый плавающий ресурс. Ресурс отпускается командой ifconfig down.
Листинг 12. Запись журнала о недостатке кворума
litsha22:~ # cat /var/log/messages .................... Jan 16 12:06:12 litsha22 ccm: [3899]: debug: quorum plugin: majority Jan 16 12:06:12 litsha22 ccm: [3899]: debug: cluster:linux-ha, member_count=1, member_quorum_votes=100 Jan 16 12:06:12 litsha22 ccm: [3899]: debug: total_node_count=3, total_quorum_votes=300 .................. Сокращено .................. Jan 16 12:06:12 litsha22 crmd: [3904]: info: crmd_ccm_msg_callback:callbacks.c Quorum lost after event=INVALID (id=15) Jan 16 12:06:12 litsha22 crmd: [3904]: WARN: check_dead_member:ccm.c Our DC node (litsha21) left the cluster .................. Сокращено .................. Jan 16 12:06:14 litsha22 IPaddr[5145]: INFO: /sbin/route -n del -host 192.168.71.205 Jan 16 12:06:15 litsha22 lrmd: [1619]: info: RA output: (IPaddr_1:stop:stderr) SIOCDELRT: No such process Jan 16 12:06:15 litsha22 IPaddr[5145]: INFO: /sbin/ifconfig eth0:0 192.168.71.205 down Jan 16 12:06:15 litsha22 IPaddr[5145]: INFO: IP Address 192.168.71.205 released Jan 16 12:06:15 litsha22 crmd: [3904]: info: process_lrm_event:lrm.c LRM operation (6) stop_0 on IPaddr_1 complete Jan 16 12:06:15 litsha22 cib: [3900]: info: cib_diff_notify:notify.c Update (client: 3904, call:32): 0.54.599 -> 0.54.600 (ok) Jan 16 12:06:15 litsha22 mgmtd: [3905]: debug: update cib finished |
Как видно из листинга 12, в случае потери заданным узлом кворума он, в соответствии с выбранной политикой отсутствия кворума, освобождает все ресурсы. Выбор политики действия в случае отсутствия кворума лежит за вами.
Сообщения и действия при аварийном переключении
Одним из наиболее интересных свойств правильно настроенной системы высокой готовности на базе Linux является то, что вам не нужно предпринимать никаких действий для восстановления работы компонента кластера. Простой активации экземпляра Linux достаточно для того, чтобы узел автоматически подключился к другим узлам. Если вы настроили основной узел (тот, который имеет предпочтение в получении плавающего ресурса над другими узлами), он автоматически будет получать плавающий ресурс. Остальные системы будут просто добавлены к пулу доступных и будут работать обычным образом.
Возврат в пул ещё одного экземпляра Linux приведет к уведомлению всех остальных узлов и, по возможности, к проведению голосования. При проведении голосования плавающий ресурс будет присвоен одному из узлов.
Листинг 13. Восстановление кворума
litsha22:~ # tail -f /var/log/messages Jan 16 12:09:02 litsha22 heartbeat: [3892]: info: Heartbeat restart on node litsha21 Jan 16 12:09:02 litsha22 heartbeat: [3892]: info: Link litsha21:eth1 up. Jan 16 12:09:02 litsha22 heartbeat: [3892]: info: Status update for node litsha21: status init Jan 16 12:09:02 litsha22 heartbeat: [3892]: info: Status update for node litsha21: status up Jan 16 12:09:22 litsha22 heartbeat: [3892]: debug: get_delnodelist: delnodelist= Jan 16 12:09:22 litsha22 heartbeat: [3892]: info: Status update for node litsha21: status active Jan 16 12:09:22 litsha22 cib: [3900]: info: cib_client_status_callback:callbacks.c Status update: Client litsha21/cib now has status [join] Jan 16 12:09:23 litsha22 heartbeat: [3892]: WARN: 1 lost packet(s) for [litsha21] [36:38] Jan 16 12:09:23 litsha22 heartbeat: [3892]: info: No pkts missing from litsha21! Jan 16 12:09:23 litsha22 crmd: [3904]: notice: crmd_client_status_callback:callbacks.c Status update: Client litsha21/crmd now has status [online] .................... Jan 16 12:09:31 litsha22 crmd: [3904]: info: crmd_ccm_msg_callback:callbacks.c Quorum (re)attained after event=NEW MEMBERSHIP (id=16) Jan 16 12:09:31 litsha22 crmd: [3904]: info: ccm_event_detail:ccm.c NEW MEMBERSHIP: trans=16, nodes=2, new=1, lost=0 n_idx=0, new_idx=2, old_idx=5 Jan 16 12:09:31 litsha22 crmd: [3904]: info: ccm_event_detail:ccm.c CURRENT: litsha22 [nodeid=1, born=13] Jan 16 12:09:31 litsha22 crmd: [3904]: info: ccm_event_detail:ccm.c CURRENT: litsha21 [nodeid=0, born=16] Jan 16 12:09:31 litsha22 crmd: [3904]: info: ccm_event_detail:ccm.c NEW: litsha21 [nodeid=0, born=16] Jan 16 12:09:31 litsha22 cib: [3900]: info: cib_diff_notify:notify.c Local-only Change (client:3904, call: 35): 0.54.600 (ok) Jan 16 12:09:31 litsha22 mgmtd: [3905]: debug: update cib finished .................... Jan 16 12:09:34 litsha22 crmd: [3904]: info: update_dc:utils.c Set DC to litsha22 (1.0.6) Jan 16 12:09:35 litsha22 cib: [3900]: info: sync_our_cib:messages.c Syncing CIB to litsha21 Jan 16 12:09:35 litsha22 crmd: [3904]: info: do_state_transition:fsa.c litsha22: State transition S_INTEGRATION -> S_FINALIZE_JOIN [ input=I_INTEGRATED cause=C_FSA_INTERNAL origin=check_join_state ] Jan 16 12:09:35 litsha22 crmd: [3904]: info: do_state_transition:fsa.c All 2 cluster nodes responded to the join offer. Jan 16 12:09:35 litsha22 attrd: [3903]: info: attrd_local_callback:attrd.c Sending full refresh Jan 16 12:09:35 litsha22 cib: [3900]: info: sync_our_cib:messages.c Syncing CIB to all peers ......................... Jan 16 12:09:37 litsha22 tengine: [5119]: info: send_rsc_command:actions.c Initiating action 4: IPaddr_1_start_0 on litsha22 Jan 16 12:09:37 litsha22 tengine: [5119]: info: send_rsc_command:actions.c Initiating action 2: probe_complete on litsha21 Jan 16 12:09:37 litsha22 crmd: [3904]: info: do_lrm_rsc_op:lrm.c Performing op start on IPaddr_1 (interval=0ms, key=2:c5131d14-a9d9-400c-a4b1-60d8f5fbbcce) Jan 16 12:09:37 litsha22 pengine: [5120]: info: process_pe_message:pengine.c Transition 2: PEngine Input stored in: /var/lib/heartbeat/pengine/pe-input-72.bz2 Jan 16 12:09:37 litsha22 IPaddr[5196]: INFO: /sbin/ifconfig eth0:0 192.168.71.205 netmask 255.255.255.0 broadcast 192.168.71.255 Jan 16 12:09:37 litsha22 IPaddr[5196]: INFO: Sending Gratuitous Arp for 192.168.71.205 on eth0:0 [eth0] Jan 16 12:09:37 litsha22 IPaddr[5196]: INFO: /usr/lib64/heartbeat/send_arp -i 500 -r 10 -p /var/run/heartbeat/rsctmp/send_arp/send_arp-192.168.71.205 eth0 192.168.71.205 auto 192.168.71.205 ffffffffffff Jan 16 12:09:37 litsha22 crmd: [3904]: info: process_lrm_event:lrm.c LRM operation (7) start_0 on IPaddr_1 complete Jan 16 12:09:37 litsha22 cib: [3900]: info: cib_diff_notify:notify.c Update (client: 3904, call:46): 0.55.607 -> 0.55.608 (ok) Jan 16 12:09:37 litsha22 mgmtd: [3905]: debug: update cib finished Jan 16 12:09:37 litsha22 tengine: [5119]: info: te_update_diff:callbacks.c Processing diff (cib_update): 0.55.607 -> 0.55.608 Jan 16 12:09:37 litsha22 tengine: [5119]: info: match_graph_event:events.c Action IPaddr_1_start_0 (4) confirmed Jan 16 12:09:37 litsha22 tengine: [5119]: info: send_rsc_command:actions.c Initiating action 5: IPaddr_1_monitor_5000 on litsha22 Jan 16 12:09:37 litsha22 crmd: [3904]: info: do_lrm_rsc_op:lrm.c Performing op monitor on IPaddr_1 (interval=5000ms, key=2:c5131d14-a9d9-400c-a4b1-60d8f5fbbcce) Jan 16 12:09:37 litsha22 cib: [5268]: info: write_cib_contents:io.c Wrote version 0.55.608 of the CIB to disk (digest: 98cb6685c25d14131c49a998dbbd0c35) Jan 16 12:09:37 litsha22 crmd: [3904]: info: process_lrm_event:lrm.c LRM operation (8) monitor_5000 on IPaddr_1 complete Jan 16 12:09:38 litsha22 cib: [3900]: info: cib_diff_notify:notify.c Update (client: 3904, call:47): 0.55.608 -> 0.55.609 (ok) Jan 16 12:09:38 litsha22 mgmtd: [3905]: debug: update cib finished |
В листинге 13 показана ситуация проведения голосования. После собрания кворума проводится голосование и litsha22 становится активным узлом, получающим плавающий ресурс.Дальнейшие действия
Высокую готовность следует рассматривать как последовательное преодоление ряда проблем, и приведенное здесь решение описывает первые шаги. Теперь у вас есть множество вариантов развития вашей среды: вы можете установить на реальных серверах резервную сеть и кластерную файловую систему, или более сложное системное программное обеспечение, поддерживающее собственно организацию кластера.
Автор: Доу Эли М, инженер-программист, IBM
Источник
2 комментов оставлено (Add 1 more)